Good note on the Venus Questions thread. I think I’ll keep the existing thread but move some of the conversations to their own threads, while tagging/ sub-categorizing those as being under Venus Questions
@Stefan doesn’t it still astound you Biomek, TECAN, or the other liquid handler company support haven’t jumped on board yet. I’ve personally heard of multiple start-up labs leaning to HAMILTON just because they heard of this forum!
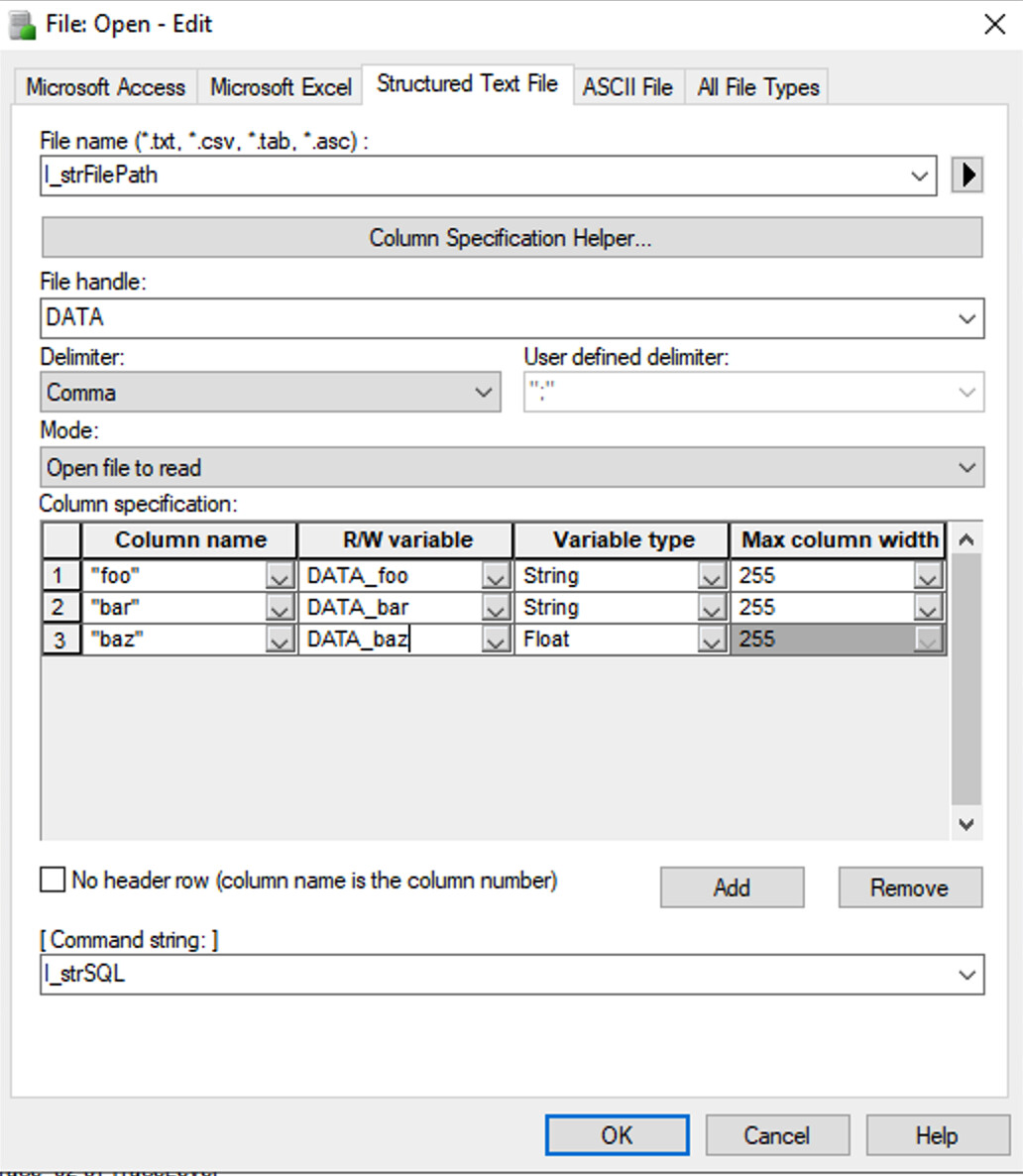
This will allow you to only read the fields of data that ascribe to your criteria. The COUNT identifier in SQL is used to simply return the number of rows that meet the criteria, and that syntax is a little different.
I think a few of them are lurking and figuring out what to make of the site and how to best engage with it. Ultimately I think just engaging with the community ad-hoc will produce massive benefits whether or not they go in with a formalized plan. The forum is a pool of customers who are eager to tell you what they want. The value in terms of market research seems pretty clear.
I’m also very optimistic about the value in helping customers with some of the troubleshooting support questions we get. If a startup has a robot and they get some critical information that helps them program that robot, that may have long-term effects on the growth of that customer’s business. A customer who is really good at writing robot code is also likely to become a big customer down the line once their business expands. Automation is that important to success, and I think a lot of people here will agree.
Being good at selling robots is good, being good at helping your customers grow their business so they can afford to buy more robots is even better.
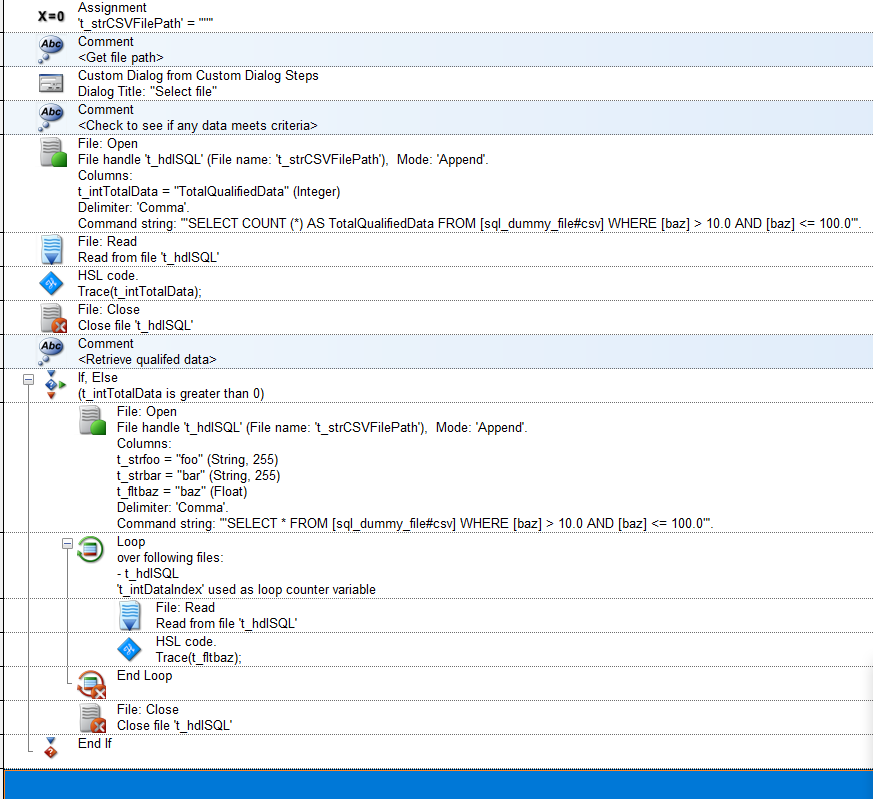
@smohler - Here is a link to a pkg containing examples that parse your file for count, as well as the original query. Hopefully this reference can rectify whatever is throwing your SQL/file open error.
The syntax for retrieving just the count is as follows:
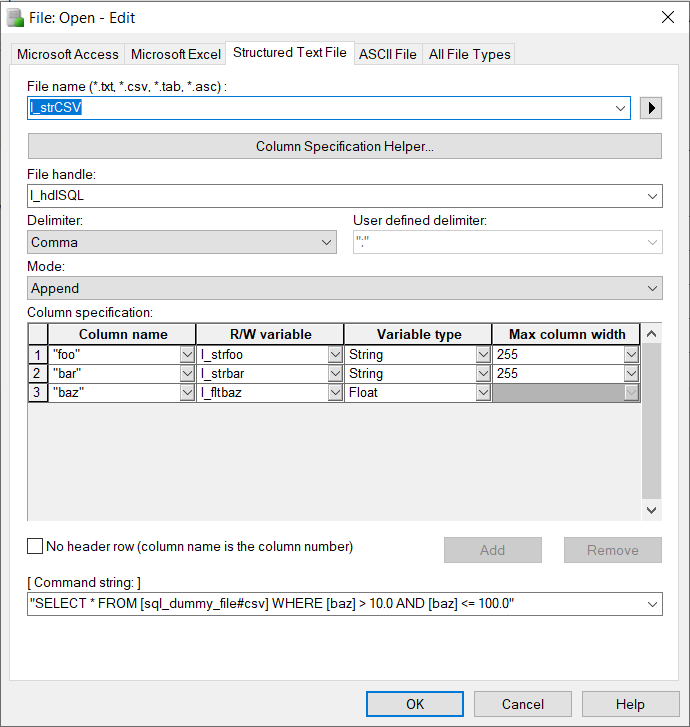
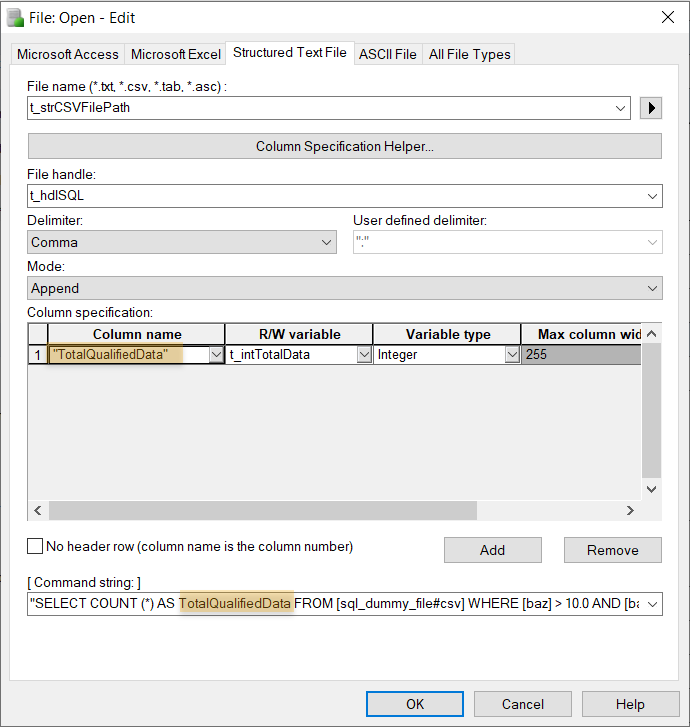
“SELECT COUNT (*) AS TotalQualifiedData FROM [sql_dummy_file#csv] WHERE [baz] > 10.0 AND [baz] <= 100.0”
Using a file open command, you essentially instantiate a temporary field that will receive the total number of data fields that match your criteria. In this example case, we are using “TotalQualifiedData” as a temporary header, where the read variable t_intTotalData receives this count value after reading from the file.
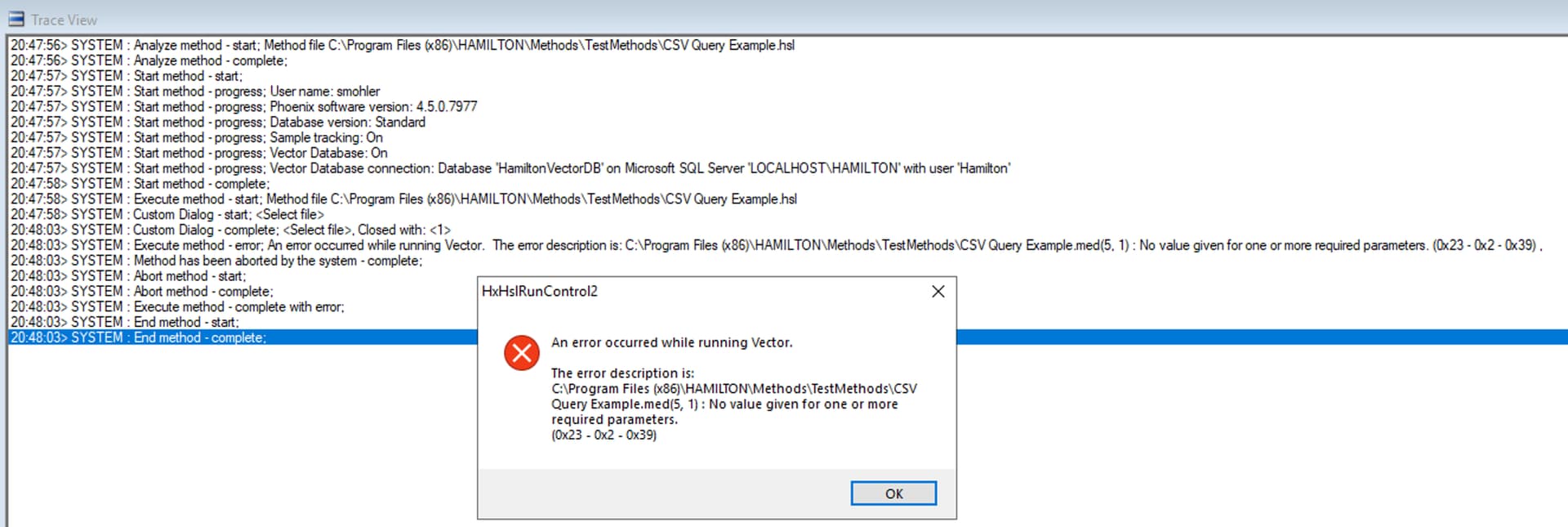
OK - I was able to reproduce the issue, and it appears to be a quirk between how VENUS handles file scripting between excel and CSV, as it pertains to this particular style of SQL query.
The reason why it was working on my machine was because the schema of the CSV (from the previous query test) was cached and at the same read location, and enabled the SQL query to work as the column format was known from the schema file. When I removed the schema file, this SQL scripting action was no longer supported.
Apparently, when calling this particular SQL command (for a CSV file) the schema must be known before the file open command containing this type of command string. I.e. the file must have been previously opened and read in an upstream command.
For an excel file, this query will work on the first read. All handling the same, except changing the syntax regarding table name (Sheet1 in this case):
“SELECT COUNT (*) AS T FROM [Sheet1$] WHERE [baz] > 10.0 AND [baz] <= 100.0”
I was not aware of this quirk until now, so apologies for leading you directly into an error.
In summary, for CSV, I would not recommend using this technique to retrieve a row count, as it requires upstream handling to work. I would do similar to what you mentioned, opening the file using the original query and then retrieving the count by looping over the file and retrieving the final value of the loop index from the read loop.